1. Invisible Index 란?
Invisible 사전적 첫번째 의미로 '보이지 않는' 이라는 뜻이 있습니다.
그럼 누구(무엇)에게 보이지 않는 다는 것일까요?
쿼리(SQL)의 실행계획을 수립하는 옵티마이저(Optimiger)에게 보이지 않는다는 의미 입니다.
실행계획을 수립하는 옵티마이저가 Invisible Index를 볼 수 없으므로, 실행계획을 수립하는데 이용할 수 없습니다.
ORACLE (11g 이상), TIBERO (6 이상) DB가 Invisible Index를 지원하고,
mysql 8.0 이후 Invisible Index 기능이 추가되었습니다. ( https://dev.mysql.com/doc/refman/8.0/en/invisible-indexes.html )
MariaDB 에도 10.6 이후 Ignored Indexes 라는 명칭으로 동일한 기능이 추가되었습니다. ( https://mariadb.com/kb/en/ignored-indexes/ )
MSSQL 과 PostgreSQL 에는 Invisible Index 개념이 없는 것으로 보이고, 가상인덱스 (Hypothetical Indexes, Virtual Indexes) 개념이 있습니다.
가상인덱스는 Invisible Index와는 달리 실제 저장공간을 차지하는 것이 아니고,
인덱스를 생성하기 전에 생성 후 쿼리(SQL)의 성능 변화를 예상실행계획을 통해 확인해 보고자 할 때 이용하는 것으로 보입니다.
( https://learn.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-indexes-transact-sql?view=sql-server-ver16 )
( https://www.postgresql.org/about/news/introducing-hypopg-hypothetical-indexes-for-postgresql-1593/ )
아래 기본적인 운영 명령어는 ORACLE / TIBERO DB 에 대한 내용으로 한정하겠습니다. (두 DB에 차이가 있을 시 명시)
1) Invisible Index 생성
Index 생성 구문에 invisible 키워드를 추가합니다.
create index 인덱스명 on 테이블명 tablespace 테이블스페이스명 invisible;
참고로 DB 라이선스에 따라 online 옵션을 추가할 수도 있고, 그 외 더 많은 옵션을 상황에 따라 선택적으로 사용할 수 있습니다.
2) 인덱스의 VISIBLE/INVISIBLE 확인
select index_name, index_type, visibility from dba_indexes -- [user_indexes]
where table_name = 'PRODUCTS'
and owner = 'TUNING'
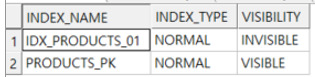
VISIBILITY 컬럼 값으로 확인할 수 있습니다.
3) VISIBLE 인덱스 / INVISIBLE 인덱스 간 전환
alter index 인덱스명 invisible; -- visible 인덱스를 invisible로 변환
alter index 인덱스명 visible; -- invisible 인덱스를 visible로 변환
2. Invisible Index 활용 방안
이 글의 주요 목적인 활용 방안 입니다.
두 가지를 기술할 건데 개인적으로 2번 내용에 더 중점을 두고 싶습니다.
1) 인덱스 Drop 전 APP 문제 발생 여부 모니터링
첫번째 활용 방안으로,
미사용 한다고 파악된 Index를 Drop 전에 Invisible로 변경하고, APP 에 문제가 생기지 않는지 모리터링 하는데 사용할 수 있습니다.
만약 APP에 문제가 생긴다면, 바로 visible로 전환해서 정상화 할 수 있습니다.
인덱스를 Drop 했다가 문제가 발생해서 재생성하게 된다면, 인덱스 생성 시간 및 부하가 발생하지만,
alter 로 visible/invisible 간의 전환은 매우 빠르게 완료되어 활용할 수 있겠습니다.
2) 인덱스를 추가하고 싶은데, SQL 영향도 분석이 어려울 때
업무를 운영하다보면, 신규 업무 추가나 기존 SQL 수행 속도 개선을 위해서, 인덱스를 신규로 추가하고자 할 때가 있을 수 있습니다.
이 때 바로 인덱스를 추가하면,
해당 테이블을 이용하는 다른 쿼리(SQL)의 실행계획이 변경 될 수도 있고, 성능 이슈로도 연결될 수 있습니다.
이럴 때 Invisible 인덱스를 활용해 볼 수 있습니다.
추가하고자 하는 인덱스를 Invisible로 생성해서,
Invisible 인덱스를 이용하고자 하는 session 에만 alter 문으로, ( alter session set optimizer_use_invisible_indexes=true; )
Invisible 인덱스를 이용하고자 하는 쿼리(SQL) 에서만 Hint를 통해서
옵티마이저(Optimiger)가 Invisible Index를 읽고 활용할 수 있게 변경할 수 있습니다.
특정 업무 SQL에 신규 인덱스를 추가하고 싶다면,
invisible 인덱스로 생성하고, 해당 SQL에
오라클 기준 /*+ use_invisible_indexes */ 힌트를
TIBERO 기준 /*+ opt_param('optimizer_use_invisible_indexes','true') */ 힌트를 통해
MySQL 기준 /*+ SET_VAR(optimizer_switch = 'use_invisible_indexes=on') */ 힌트를 통해
해당 SQL 만 신규 Invisible 인덱스를 이용할 수 있도록 할 수 있습니다. (mariadb의 경우 힌트를 통한 제어는 확인할 수 없었습니다.)
위 힌트는 Invisible 인덱스를 이용할 수 있도록 하는 것이지, 무조건 Invisible 인덱스를 타도록 실행계획을 수립하라는 힌트는 아닙니다.
옵티마지저가 기존 visible 인덱스와 신규 Invisible 인덱스를 모두 고려해서 최적이라고 판단하는 실행계획을 수립하게 됩니다.
그래서, 필요에 따라 신규 Invisible 인덱스를 이용하기 위해서 index 힌트를 추가적으로 명시해야 할 수도 있습니다.
3. Invisible Index 활용 예시
아래는 Products 라는 테이블에 COLOR 컬럼으로 신규 Invisible 인덱스를 추가하고,
특정 SQL에서만 Invisible 인덱스를 사용할 수 있게 하는 테스트 내용입니다.
테이블 컬럼 정보
desc TUNING.PRODUCTS;

-- color 컬럼의 분포도 ( 전체 데이터 대비 'RED' 값의 비율이 9% 정도로 Full Table Scan이 성능에 더 유리 )
select color, count(*), round(count(*)/(sum(count(*)) over()) * 100, 2) as row_pct
from TUNING.PRODUCTS
group by color order by 2 desc;

0. 파라미터 확인
-- 오라클
select name, value, default_value, issys_modifiable from v$parameter where name ='optimizer_use_invisible_indexes';

-- Tibero
SELECT * FROM v$parameters WHERE name ='OPTIMIZER_USE_INVISIBLE_INDEXES';

1. Invisible 인덱스 생성 전
select * from products where color = 'RED';

실행계획을 보면 Full Table Scan을 하고 있습니다.
2. Invisible 인덱스 생성 후
-- invisible 인덱스 생성
create index idx_products_01 on PRODUCTS(color) invisible;
select * from products where color = 'RED';

Invisible 인덱스 생성해도 변함없이 Table Full Scan 하고 있습니다.
3. idx_products_01 인덱스 힌트 추가
select /*+ index(products idx_products_01) */ * from products where color = 'RED';

Color 컬럼의 'RED' 값의 분포도 때문에 옵티마이저가 Full Table Scan을 하는 것을 수도 있어서
신규 Invisible 인덱스를 타도록 힌트로 명시했슴에도, Invisible Index를 이용못하고 Full Table Scan 합니다.
단, 위 결과는 Oracle DB에서의 결과였고,
Tibero 6 에서는 Invisible 인덱스를 생성하고 힌트로 invisible 인덱스를 명시하는 것 만으로도 Invisible 인덱스를 이용했습니다. (bug 같습니다.)
Tibero에서 select /*+ index(products idx_products_01) */ * from products where color = 'RED'; 수행 시 실행계획

4. opt_param 힌트 사용
oracle DB에서 Hint를 통해 파라미터 설정을 변경하고자 할때, 일반적으로 opt_param 힌트를 사용합니다.
opt_param 힌트 사용해서 optimizer_use_invisible_indexes 파라미터를 변경하는 것으로 테스트 해봤습니다.
select /*+ opt_param('optimizer_use_invisible_indexes','true') index(products idx_products_01) */ * from products
where color = 'RED';

신규 인덱스를 타라는 힌트 까지 주었는데도, 여전히 Full Table Scan 합니다. opt_param 힌트로는 Invisible 인덱스를 이용하게 할 수 없었습니다.
5. use_invisible_indexes 힌트만 사용 (index 힌트 없이)
select /*+ use_invisible_indexes */ * from products
where color = 'RED';
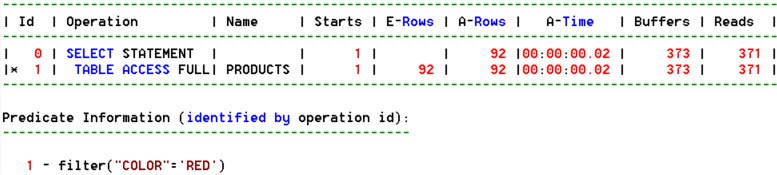
use_invisible_indexes 힌트를 써도, COLOR 컬럼의 'RED' 값의 분포도 때문에 옵티마이저는 Full Table Scan이 더 좋다고 판단 Full Table Scan 합니다.
6. use_invisible_indexes 힌트와 Index 힌트 사용
select /*+ use_invisible_indexes index(products idx_products_01) */ * from products
where color = 'RED';

이제서야 신규 Invisible 인덱스를 타는 것을 확인 할 수 있었습니다.
마무리하며,
DB를 운영하는 중에 인덱스를 추가해야 하는 상황이 생겼는데,
인덱스 추가로 인해 해당 테이블을 사용하는 모든 쿼리(SQL)에 대한 영향도 분석이 어렵다면,
Invisible 인덱스를 이용해서, 해당 SQL에만 신규 인덱스를 활용할 수 있도록 운영해 보면, 신규 인덱스 생성으로 인한 성능 이슈를 피할 수 있지 않을까 싶습니다.
단, Invisible 인덱스도 저장공간 차지 및 DML 발생 시 인덱스 갱신 부하는 동일하게 있으므로
무분별하게 Invisible 인덱스를 생성하는 것은 지양해야 할 것입니다.
'일 > 개발, IT정보' 카테고리의 다른 글
| Oracle 백업 복구의 개념, 개념, 절차 (0) | 2024.10.25 |
|---|---|
| MS-SQL 분할 뷰, 파티션 개념 및 관리 방법 (1) | 2024.10.21 |
| Cisco Catalyst 스위치 제품 번호 읽는 방법 (0) | 2024.10.20 |
| UDF와 Scalar T-SQL UDF Inlining (0) | 2024.10.19 |
| 오라클 DB RECYCLEBIN 관리 및 사용법 (0) | 2024.10.17 |



